To get the
massive amount of text within the 19th century renovated court
records into a computer readable form, we use Transkribus to train HTR models
to transcribe automatically the hand written text in the court records. Talking
about HTR models can turn into a sea of acronyms pretty quickly, so it would
probably be best to start with some key terminology, although some of them have
already come up in previous blogs.
Ground Truth or GT refers
to the set of human transcribed pages used in training of the HTR models.
CER and WER are
used to measure the accuracy of the HTR model, CER meaning character error rate
and WER meaning word error rate. These show the average percentage of
characters or words the model has recognized incorrectly.
Now, handwriting
is not uniform. Any given person has their own style of handwriting, some
people write neatly, and others have super messy handwriting. On top of that, writing
styles change over time; this is why reading old texts usually takes at least
some amount of training. So, you need to train a specific HTR model for the material
you’re working with, although there are efforts to generate more generalized
models.
The
renovated court records present multiple challenges to HTR models: the time
span of almost a century, regional variations, and many different writers. In
order to generate a reliable model to a material with a lot of variation in
writers and hands, the set of ground truth must be considerably larger than,
say, in models used to recognize only one person’s hand.
Transkribus’
user manual recommends starting with a GT of about 100 pages (20 000
words) to create an HTR model for one hand. The current models used for
recognizing renovated court records are made with 500 images of GT (about
175 000 words, give or take) from the years 1850 to 1871. We are currently
proofreading transcriptions for 500 images more to get even better generalized
model of 19th century Swedish hand for the court records, especially
concerning the first half of the century.
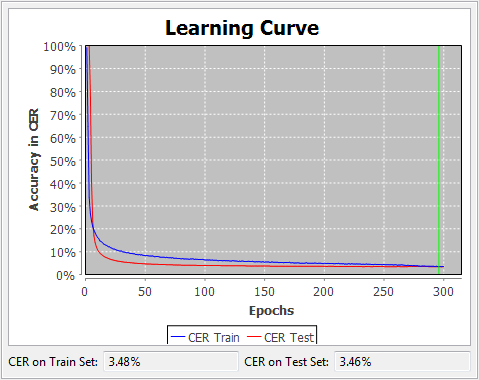 |
| A HTR model's learning curve |
Training a HTR model with Transkribus is a fairly straightforward process, or at least the
part needing human work is. You fill in the basic information of the model
(name, language, and description), you split your GT into a training set and
testing set, and set the number of training epochs, or the times the neural
network evaluates the training data (and learning rate, noise, and train size
per epoch, if you’re working with the older CTIlab HTR engine). The test set
portion of the GT is not used in the training itself, but it is used as a
reference point to calculate the CER of the model during the training. After
that, it’s all up to the computer. The training of the model can take anywhere
between hours and days, depending on the amount of training material and
training epochs.
We have
models made with the whole set of 500 pages as well as tests with smaller sets
with GT only from a certain decade. With the new HTR+ engine the models’ CER
range from 5% to 3%. When we have run the models on pages from the renovated
court records not used in the models’ GT, the CER for more general models vary
from 3% to 8%, depending on the text they are run on. The models for certain
decades have a CER of 6% to 9% on texts from their corresponding decades.
It is a bit
hard to convey how well a model recognizes text using only error rates. I don’t
think too many people can say from the top of their head how legible a text is
if I tell them that the text has, say, approximately seven incorrect characters
for every hundred characters. So as a more tangible demonstration, from left to
right, the images below show human transcribed text, the same text recognized
with one of the latest models for court records with a 3.5% CER, and the text
recognized with an older model with a 9.1% CER.
 |
| Sample of HTR models run on a page from the court records from the rural district of Åland (click to view larger image) |
This
example is, of course, a very, very well performing and a fairly well
performing model run on a page with extremely legible handwriting (the CERs
calculated for this page are 3.3% and 12.9%, respectively). As a rule of thumb,
if the page hard for a human to read it properly (be it because of the writing
style or problems with the image itself), it is also going to be hard to
decipher for the neural network, and vice versa.
It remains
to be seen (hopefully not for too long, though) how the new set of GT affects
the performance of our recognition models.
Kaisa Luhta
Comments
Post a Comment