The subject of making full text searches possible in district court records was touched on the blog about Turku book fair some time ago, and now it’s time to take a deeper dive into how exactly the full text searching works.
The key to the search tool is keyword spotting (KWS). Keyword spotting
technology uses confidence matrices to find matching images to your
search term. The confidence matrices are based on the HTR model run on
the text you want to search: The HTR model assigns each letter in the
alphabet a value of how certain the model is that that letter
corresponds with that part of the image (ie. a section of a word on a
row) when you run the model on a page. The transcription the model
outputs is essentially the letters and words the model is the most
confident match the image.
 |
| High confidence result for the search "äktenskap". |
 |
| Low confidence result for the search "äktenskap". The confidence is low because the found word is actually "äktenskaps". |
Unfortunately, the search result the model is most confident of is not always the correct one. This is why machine-made transcriptions are not 100% correct, even with models with low character error rate (CER), and can be full of mistakes with models that have high CER. With KWS the search is not performed in the outputted transcription, but in the confidence matrices. This means that you can also search images where the transcription’s CER is relatively high (20-30%). However, this also means that the model’s highest confidence result might not be the search term you entered. This might occur especially on images that have high CER, or if your search term has letters or letter combinations that closely resemble other letters in the image (for an example, k and h, a and u, and e and c can be easily confused with each other in a lot of hands). This is why KWS is useful in materials transcribed using HTR: the correct search term is also found, it just might be lower on the model’s confidence list. Lower confidence level on the search means you can find results that are lower on the model’s confidence list. Of course, if your search term is low on the model’s confidence list, by lowering the confidence you might also get even more false positives in your search results.
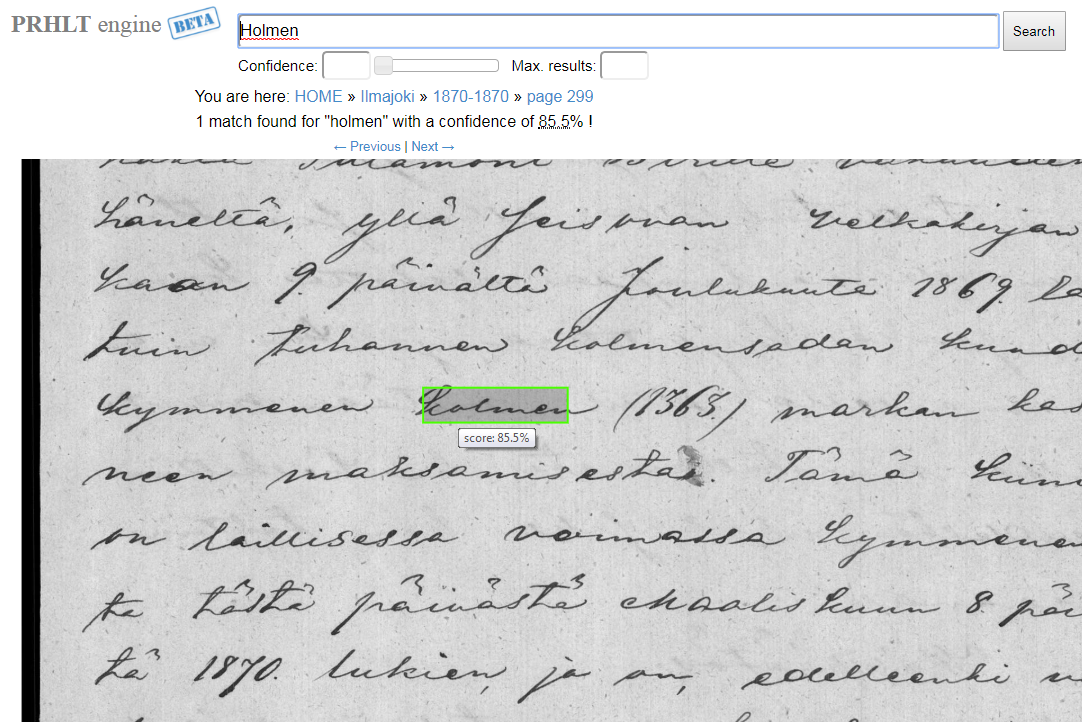 |
| High confidence result for the search "Holmen", which is actually a false positive ("kolmen"). |
 |
| Low confidence result for the search "Holmen", which is correct. |
In order to make the keyword spotting possible, the material needs to be processed and indexed. Search indexing speeds up the time it takes for the engine to search the material. It is especially useful when you search large-scale materials, such as court records. Our search index is provided by the Pattern Recognition and Human Language Technology research center at the Universitat Politècnica de València. Some elements of the indexing are layout analysis, line detection and enhancing of the images. These processes enable the computer to recognize text regions and lines when performing searches. These are all automated processes but nonetheless time consuming, as the indexing time of one page is approximately one minute. In the demo version, we have ca 138 133 indexed pages and by the end of this year, Valencia will continue to index the rest of the court district material which is about 1 million pages. In addition to these layout processes you need to train optical and language models with the ground truth, the transcribed text that we produce when we develop our HTR-models (you can read our blog post about model training
here).
So, the main advantage of KWS is that with it the computer-generated transcription doesn’t have to be perfect, because the searches are not performed in the transcription. Even though we have achieved models with tremendously low CER, the machine-made transcriptions are still not 100% accurate, and pages that are less legible than average are going to have higher CERs. Utilizing KWS in the search tool we can ensure that also less legible pages are searchable alongside of more clear ones.
We are confident that keyword spotting will have a big impact on future research, and we are happy to be a part of the development. You can try Valencia’s demo tool and keyword spotting
here.
Kaisa Luhta & Hanna Strandberg
Hey, thanks a lot for sharing such an informative blog with us. Keep on sharing such blogs with us. I have recently completed my digital marketing course from Learn Digital Academy. They have a very good faculty, who help you learn each and every aspect of digital marketing.Advanced Digital Marketing Course In Bangalore
ReplyDeleteThanks for this blog.
ReplyDeletechocolate tea in pakistan
Good bog post.
ReplyDeletefire alarm system
hearing aid Pakistan
hearing aids in lahore
custom suits
ad agency
calcium carbonate manufacturers
Architecture Designs in lahore
hearing clinic in lahore
Termite Treatment in lahore
This comment has been removed by the author.
ReplyDeleteFor healthy weight loss supplement.
ReplyDeleteGood post
ReplyDeleteKeyword spotting is truly a game-changer in the search world! Finding a reliable digital marketing agency near you has never been easier thanks to this effective tool. Say goodbye to endless searching and hello to success!
ReplyDeleteI highly recommend Digital Marketing in Faridabad by Designyze. Their expert team knows how to optimize local SEO, run effective ads, and build a strong online presence that attracts the right audience.
ReplyDelete